Your Genesys Blog Subscription has been confirmed!
Please add genesys@email.genesys.com to your safe sender list to ensure you receive the weekly blog notifications.
Subscribe to our free newsletter and get blog updates in your inbox
Don't Show This Again.

Artificial intelligence (AI) practitioners are often asked to show their work. They have to prove that their AI technology works and is on par with — or better than — an alternative AI solution. It seems like a reasonable request. But measuring AI quality is difficult at best and, in some cases, it’s just impossible. There are measures that are used for testing AI — error rates, recall, lift, confidence — but many of them are meaningless without context. And with AI, the real KPI is ROI.
That’s not to say that all AI technology is built the same or that quality is irrelevant. The quality of your AI solution has a material impact on your ability to use AI to achieve ROI. In this blog, I’ll examine AI quality benchmarks and concepts as well as some best practices. This can serve as a reference point for those at any stage of the AI implementation journey.
Some expect AI to be consistently accurate. The perception is that AI will correct human flaws and, since human error is inevitable and expected, AI must be its opposite. Achieving this level of perfection is an impossible standard. Expectations need to be realistic; the best way to measure AI success is business impact.
There are some things that AI can in the contact centre that a human can’t. For example, even if a chatbot can only answer one question, it can still answer that one question 24/7 without ever stopping for a break. If that question is important to a large percentage of customers, or a small but important customer segment, then that chatbot has value well beyond its ability to accurately understand and respond conversationally to a wide set of requests.
For conversational AI, expectations of perfection are sure to disappoint.
Conversational AI bots are trained on data and the quality of the underlying natural language understanding (NLU) model depends on the data set used for training and testing. You might have seen some reports that show NLU benchmarks. When reviewing the numbers, make sure you understand what data was used.
Let’s say Vendor A used the same training and testing data for the analysis, but vendors B and C had a different training data set. The results for Vendor A will likely outperform Vendor B and C. Vendor A is (essentially) using birth year to predict age, which is a model that is 100% accurate but likely not the best use of AI.
NLU models are measured using these dimensions:
In the case of conversational AI, a positive prediction is a match between what a customer said and what a customer meant. Quality analysis compares how well the NLU model understands natural language. It doesn’t measure how the conversational AI responds to what has been asked.
Your NLU model might be able to capture what the customers want accurately. However, your framework might not be able to connect to the systems it needs to satisfy the asks, transition the call to the right channel with context preserved or identify the right answer to the question. NLU accuracy is not a proxy for customer satisfaction or first-contact resolution.
Scores are typically a point-in-time evaluation and are highly dependent on the data used for the analysis. Differences in scores might be difficult to interpret (unless you’re a linguistic model expert). For example, if one NLU has a score of 79% and another has a score of 80%, what does that mean? Published comparisons often don’t include — or include as very fine print — the scope of the test, how many times a test was run and rarely provide the actual data used.
If you’re considering an off-the-shelf, pre-trained bot, then having these benchmarks could be useful. But you may need to expand your evaluation to incorporate other factors such as the ability to personalise, analyse and optimise. More about that later.
For those who are using Genesys AI to build and deploy bots, NLU models are as unique as our customers. They’re trained for purpose — using data that’s either customer-specific or is specific to the use case the customer is trying to solve. Standard benchmark reports wouldn’t do Genesys AI justice. However, teams regularly test the performance of Genesys NLU versus others using standard corpus (Figure 1).
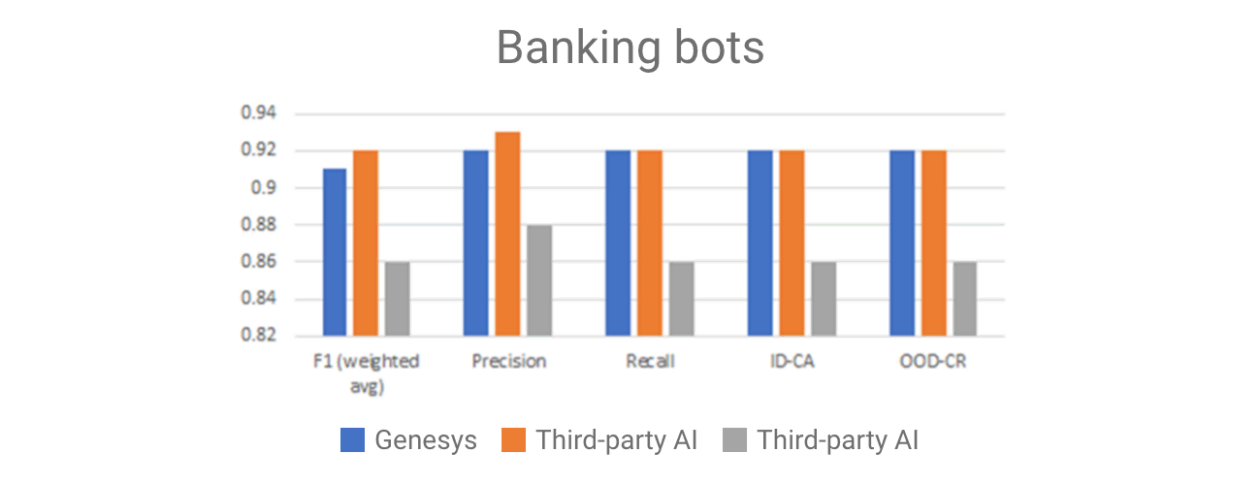
“Banking bot” is trained using a standard data set that represents the many self-service requests that are typical for a bank. This test shows that Genesys NLU is on par with some third-party AI and performs better on this test than others. When we expand the test to other languages, results vary.
This test was performed with the same dataset translated (by a human) to the various languages represented below. If trying to compare NLU providers based on benchmarks alone, language is an important dimension. Some NLUs work particularly well with one set of languages but not as well with others (Figure 2).
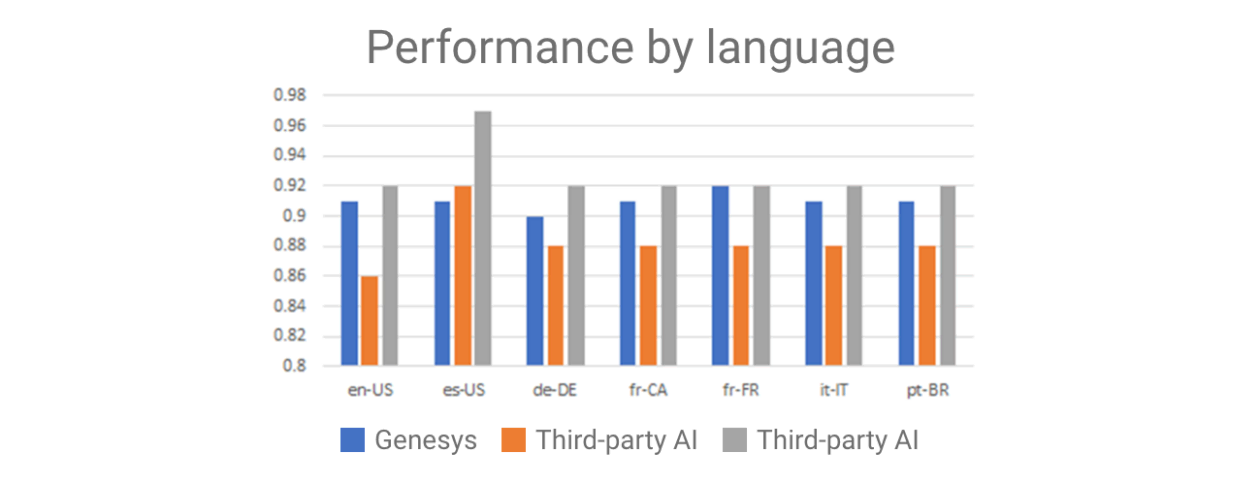
Consider the results: These and many other test results are used to fine-tune the underlying components to ensure that those who are creating bots can achieve the same or better level of NLU with their bot than they would through other popular NLU options.
Bot are built for real-world use, not test data sets. We need to have a feel for how a model performs on data that is representative of the actual mix of incoming end-user queries for the use case that the bot has been created to address. A “representative” test set will take a snapshot of actual (anonymised) customer utterances. This can be manual or automated.
The intent distribution will be very unbalanced, since there’s usually a small number of intents that are the most frequent reasons customers are initially contacting your bot. And after a bot has gone through fine-tuning, the most frequent customer utterances will be part of the model; only those that aren’t addressed will remain. This type of test set measures in-the-field performance and is critical for maintaining quality over time.
NLU models are the foundation for conversational AI bots. An NLU model predicts the end user’s intent and extracts slots (data) by being trained using a set of example utterances, which typically consist of different ways a customer asks a question.
Comprehensive bot authoring tools give the bot creator the ability to add and train the intents and slots required for their bot, while also providing analytical tools to learn how the bot is performing — and tools to improve the NLU model over time.
Generic NLU models might do a good job understanding basic questions, but customer service isn’t generic. The specificity that bots need to be effective comes from the training data (corpus) used during the training process. The closer the training data represents actual conversations, the better the bot will perform. One way to get better data is to use the actual conversations.
A best practice would be to implement conversational AI technology with a tool that can extract intents and the utterances that represent those intents from actual conversations — from voice or digital. It’s important to have a way to test the bot prior to deployment and to capture any missed intent identification post-deployment. Conversational AI quality isn’t static.
Bots can improve over time if there’s a way to optimise them post-deployment. This can be difficult with off-the-shelf bots that need custom development.
A major advantage of having an integrated bot framework is that you can course correct bots that aren’t performing as expected in real time without disruption. When thinking about quality, ask about optimisation. Is optimisation automatic? Is there a human-in-the-loop process? How can you, as the business, “see” what’s happening?
Bias should be part of the quality discussion. Bias in AI is inevitable. What’s critical isn’t where bias exists (it does) — but how well the bot can recognise it and trace it back to the source.
If you are using a pre-trained model (an off-the-shelf bot), you likely don’t know its training set. Even a large corpus drawn from a wide set of industry content can be biased if that source represents a single geography or a specific point in time. Examples of built-in bias that have derailed AI projects are out there; many AI projects are impossible to correct enough to be practical.
Bias is of particular interest for those looking to use pre-trained large language models (LLMs). The advantage of having off-the-shelf, ready-to-go large models is that they’re highly conversational and have been exposed to a wide variety of conversational patterns. However, the training sets are so large that they’re hard to curate, and they depend on the ability of the vendors to find and use data that’s truly impartial. A recent paper shows that LLMs are partisan — which you may want to consider when asking questions about politics or events. A partisan bias could alter the information you’re receiving (Figure 3).
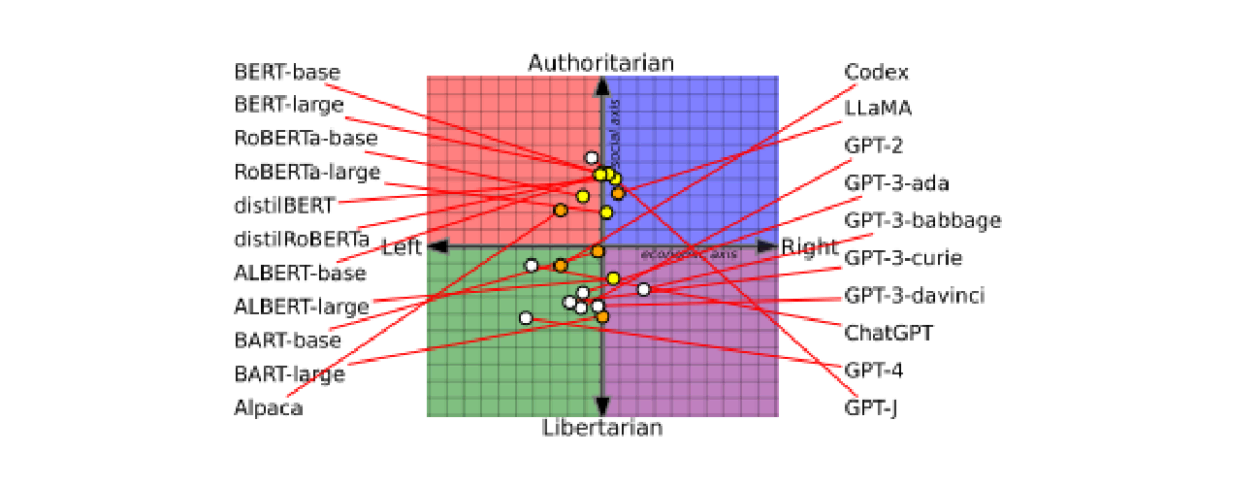
When embarking on an AI project, start with the goal and the output. What is the AI project meant to accomplish (automate) and what would the impact be to that accomplishment if the data used contains bias that will materially alter the decision?
For example, a model that’s used to automate loan approval or employment that’s biased can yield a decision that’s unethical and likely illegal in most countries. The mitigation strategy is to avoid use of data such as age, gender and racial background. But often, within the data, measures exist that are related to these protected categories that could drive the output and introduce the wrong type of bias into the model.
For some sensitive decisions, such as employment, the use of AI is highly regulated and monitored (as it should be). When considering the outcome of conversational AI, bias might not have a significant impact on the conversation. While it should be considered, its impact is unlikely to have the type of business impact a biased employment model would. To evaluate and consider bias, start with the outcome and work your way back to the data.
The source of bias is the training data. An employment model that was trained on data from a point in time when employment practices precluded certain groups from employments or specific roles will bring this bias forward into the modern day. Making sure data is well balanced is one way to control for bias.
For conversational AI and for AI-enabled customer experience automation, use actual conversational data from your own customer base as that represents the possible conversations. Built-in analytics enable users to assess whether there is bias in how the bot is responding. Watching how intents are derived from utterances, as well as which utterances are understood and which aren’t, will show if there is bias potential.
A built-in feedback mechanism can help capture any issues and the optimisation tools enable organisations to adjust a bot. This isn’t an unattended process that can run amuck.
This is very much controlled, measured and optimised with a human-in-the-loop process. This means that this can work for both highly sensitive information and for general information. Some forms of AI can only do one or the other, which will limit its efficacy.
Contact centres need conversational AI that provides a quality response to your customers and advances your business objectives. The temptation to search for benchmark reports and engineering specifications might yield a lot of data that could be hard to understand and is unlikely to help you meet your goals.
It’s important to have a solution that has the following characteristics:
Learn more about the Genesys approach to conversational AI with this video.
 Rahul Garg
Rahul Garg
Rahul joined Genesys in 2021 as VP of Product, AI and Digital Self-Service. He’s focused on building the best conversational AI products for Genesys Cloud. Prior to Genesys, he worked...
Subscribe to our free newsletter and get the Genesys blog updates in your inbox.


