Ihr Abonnement des Genesys-Blogs wurde bestätigt!
Please add genesys@email.genesys.com to your safe sender list to ensure you receive the weekly blog notifications.
Abonnieren Sie unseren kostenlosen Newsletter und erhalten Sie alle Updates zum Blog bequem in Ihre E-Mail-Inbox.
Diese Meldung nicht mehr anzeigen.

Experten für künstliche Intelligenz (KI) werden oft gebeten, ihre Arbeit zu demonstrieren. Sie müssen beweisen, dass ihre KI-Technologie funktioniert und sich mit einer alternativen KI-Lösung messen kann oder besser ist als diese. Das scheint ein gerechtfertigtes Anliegen zu sein. Doch das Messen der KI-Qualität ist schwierig und in einigen Fällen sogar unmöglich. Es gibt Maßeinheiten, die zum Testen von KI verwendet werden: Error Rates, Recall, Lift, Confidence. Aber viele von ihnen sind ohne Kontext bedeutungslos. Und bei KI ist der echte KPI der ROI. Das heißt nicht, dass alle KI-Technologien gleich aufgebaut sind oder dass die Qualität irrelevant ist. Die Qualität Ihrer KI-Lösung wirkt sich wesentlich auf Ihre Fähigkeit aus, mit der KI ein ROI zu erzielen. In diesem Blog werde ich Benchmarks für die KI-Qualität, Konzepte und Best Practices beleuchten. Dies kann als Bezugspunkt für diejenigen dienen, die sich in irgendeiner der Phasen der KI-Implementierung befinden.
Einige erwarten, dass KI immer akkurat ist. Viele Menschen glauben, dass KI menschliche Fehler korrigiert und dass KI, da menschliche Fehler unvermeidlich und erwartbar sind, das Gegenteil davon sein muss. Diese Perfektion erreichen zu wollen, ist ein unmögliches Vorhaben. Die Erwartungen müssen realistisch sein. Der beste Weg, den Erfolg von KI zu messen, sind die geschäftlichen Auswirkungen. Es gibt einige Dinge, die KI im Contact Center leisten kann, die ein Mensch nicht kann. Selbst wenn ein Chatbot beispielsweise nur eine Frage beantworten kann, kann er dennoch diese Frage rund um die Uhr beantworten, ohne jemals eine Pause einzulegen. Wenn diese Frage für einen Großteil der Kunden oder ein kleines, aber wichtiges Kundensegment wichtig ist, hat der Chatbot einen großen Wert, der weit über seine Fähigkeit hinausgeht, eine Vielzahl von Anfragen genau zu verstehen und auf diese dialogorientiert zu reagieren. Bei der dialogorientierten KI werden die Erwartungen an Perfektion mit Sicherheit nicht erfüllt. Dialogorientierte KI-Bots werden mit Daten trainiert. Die Qualität des zugrunde liegenden Natural Language Understanding (NLU)-Modells hängt von dem für das Training und die Tests verwendeten Datensatz ab. Vielleicht haben Sie einige Berichte gesehen, die NLU-Benchmarks enthalten. Stellen Sie bei der Überprüfung der Zahlen sicher, dass Sie verstehen, welche Daten verwendet wurden. Nehmen wir an, Anbieter A hat die gleichen Trainings- und Testdaten für die Analyse verwendet, aber Anbieter B und C hatten einen anderen Datensatz für das Training. Die Ergebnisse für Anbieter A werden wahrscheinlich die Ergebnisse von Anbieter B und C übertreffen. Anbieter A verwendet (im Prinzip) das Geburtsjahr, um das Alter vorherzusagen. Dies ist ein zu 100 % genaues Modell, jedoch wahrscheinlich nicht die beste Nutzung von KI.
NLU-Modelle werden mit diesen Dimensionen gemessen:
Im Fall der dialogorientierten KI ist eine positive Vorhersage eine Übereinstimmung zwischen dem, was ein Kunde gesagt hat, und dem, was ein Kunde gemeint hat. Bei der Qualitätsanalyse wird verglichen, wie gut das NLU-Modell natürliche Sprache versteht. Es misst nicht, wie die dialogorientierte KI auf die gestellten Fragen reagiert. Ihr NLU-Modell kann möglicherweise genau erfassen, was die Kunden wünschen. Ihr Framework ist jedoch möglicherweise nicht in der Lage, eine Verbindung zu den Systemen herzustellen, die es benötigt, um die Anfrage zufriedenstellend zu beantworten, den Anruf unter Beibehaltung des Kontexts zum richtigen Kanal zu leiten oder die richtige Antwort auf die Frage zu finden. Die NLU-Genauigkeit steht nicht stellvertretend für die Kundenzufriedenheit oder die Problemlösung beim ersten Kontakt (First-Contact-Resolution). Scores sind in der Regel eine Bewertung zu einem spezifischen Zeitpunkt und hängen stark von den für die Analyse verwendeten Daten ab. Unterschiede bei den Bewertungen sind möglicherweise schwer zu interpretieren (es sei denn, Sie sind Experte für linguistische Modelle). Wenn zum Beispiel ein NLU-Modell einen Score von 79 % und ein anderes einen Score von 80 % hat, was bedeutet das? Veröffentlichte Vergleiche enthalten oft nicht – oder nur im Kleingedruckten – den Umfang des Tests oder die Häufigkeit, mit der ein Test durchgeführt wurde, und sie liefern selten die tatsächlich verwendeten Daten. Wenn Sie einen vorgeschulten Standard-Bot in Betracht ziehen, könnte es hilfreich sein, diese Benchmarks zu haben. Möglicherweise müssen Sie Ihre Bewertung jedoch erweitern, um andere Faktoren einzubeziehen, wie Personalisierungs-, Analyse- und Optimierungsfähigkeiten. Mehr dazu später. Für diejenigen, die Genesys AI zum Erstellen und Bereitstellen von Bots verwenden, sind die NLU-Modelle so einzigartig wie unsere Kunden. Sie werden zweckorientiert mit Daten geschult, die entweder kundenspezifisch oder spezifisch für den Anwendungsfall sind, den der Kunde versucht zu lösen. Herkömmliche Benchmark-Berichte würden Genesys AI nicht gerecht. Viele Teams testen jedoch regelmäßig die Leistung des Genesys NLU-Modells im Vergleich zu anderen unter Zuhilfenahme eines Standard-Korpus (Abbildung 1).
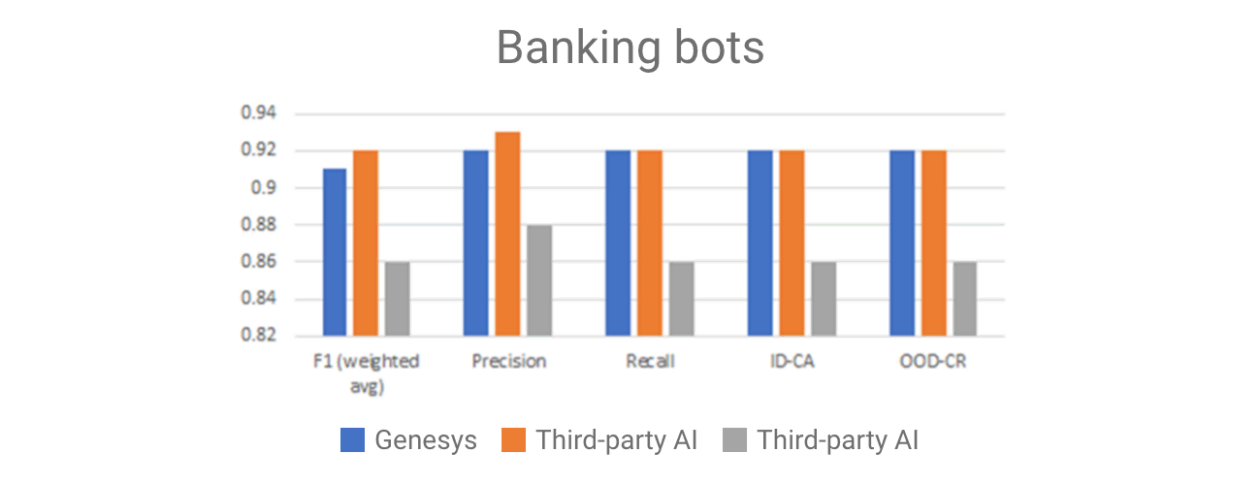
Der „Banking-Bot“ wird anhand eines Standarddatensatzes trainiert, der die vielen Self-Service-Anfragen abbildet, die für eine Bank typisch sind. Dieser Test zeigt, dass sich das Genesys NLU-Modell mit einigen Drittanbieter-KIs messen kann und in diesem Test eine bessere Leistung erbringt als andere. Wenn wir den Test auf andere Sprachen erweitern, variieren die Ergebnisse. Dieser Test wurde mit demselben Datensatz durchgeführt, der (von einem Menschen) in die verschiedenen unten aufgeführten Sprachen übersetzt wurde. Wenn Sie versuchen, NLU-Anbieter allein auf der Grundlage von Benchmarks zu vergleichen, ist Sprache eine wichtige Dimension. Einige NLU-Modelle funktionieren besonders gut mit einem Sprachensatz, aber nicht so gut mit anderen (Abbildung 2).
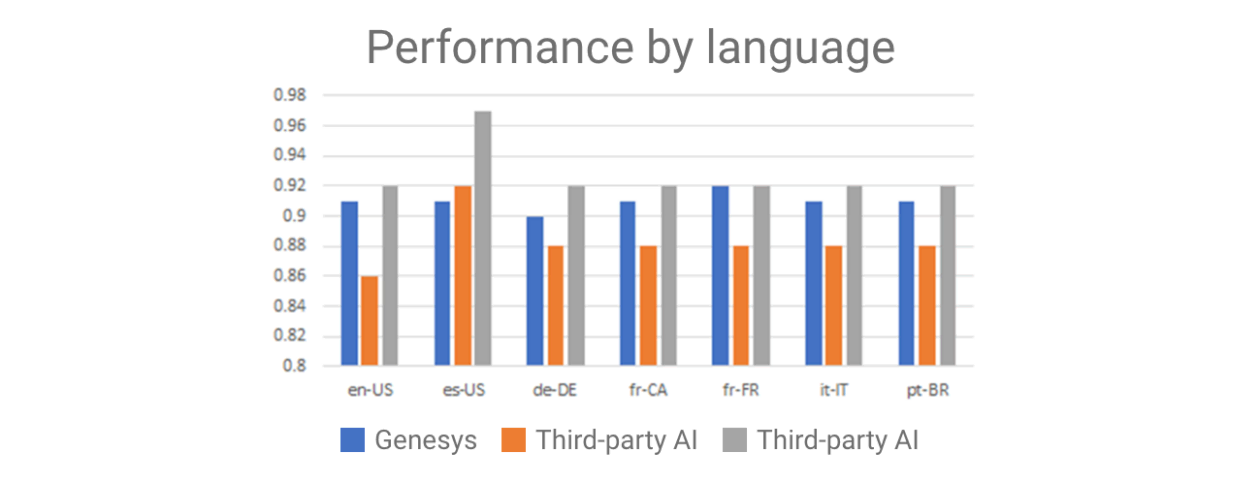
Wägen Sie die Ergebnisse ab: Diese und viele andere Testergebnisse werden zur Feinabstimmung der zugrunde liegenden Komponenten verwendet, um sicherzustellen, dass diejenigen, die Bots erstellen, mit ihrem Bot dasselbe oder ein besseres NLU-Niveau erreichen können als mit anderen beliebten NLU-Optionen.
Bots sind für den Einsatz im echten Leben konzipiert, nicht für das Testen von Datensätzen. Man muss ein Gefühl dafür haben, welche Leistung ein Modell mit Daten erbringt, die repräsentativ für die vielfältigen, tatsächlich eingehenden Endbenutzer-Anfragen für den Anwendungsfall sind, für den der Bot erstellt wurde. Ein „repräsentativer“ Testsatz erstellt eine Momentaufnahme der tatsächlichen (anonymisierten) Äußerungen von Kunden. Dies kann manuell oder automatisch erfolgen. Die Intentionsverteilung ist sehr unausgewogen, da es in der Regel nur eine geringe Anzahl von Intentionen gibt, die die häufigsten Gründe sind, warum Kunden Ihren Bot überhaupt kontaktieren. Nach der Feinabstimmung des Bots, werden die häufigsten Äußerungen von Kunden Teil des Modells sein; nur die, die nicht angesprochen werden, bleiben übrig. Diese Art von Testsatz misst die Leistung unter Praxisbedingungen und ist entscheidend für die Aufrechterhaltung der Qualität über einen längeren Zeitraum. NLU-Modelle sind die Grundlage für dialogorientierte KI-Bots. Ein NLU-Modell prognostiziert die Intention des Endnutzers und extrahiert Slots (Daten), indem es anhand einer Reihe beispielhafter Äußerungen trainiert wird, die in der Regel aus verschiedenen Möglichkeiten bestehen, wie ein Kunde eine Frage stellt. Umfassende Tools zur Erstellung von Bot-Inhalten ermöglichen es Bot-Entwicklern, die für ihren Bot erforderlichen Intentionen und Slots hinzuzufügen und zu trainieren. Darüber hinaus bieten sie Analysetools, mit denen man sehen kann, welche Leistung der Bot erbringt, sowie Tools zur Verbesserung des NLU-Modells im Laufe der Zeit. Generische NLU-Modelle können möglicherweise grundlegende Fragen gut verstehen, aber Kundenservice ist nicht generisch. Die Spezifität, die Bots benötigen, um effizient zu sein, ergibt sich aus den Trainingsdaten (Korpus), die während des Trainingsprozesses verwendet werden. Je genauer die Trainingsdaten tatsächliche Gesprächen abbilden, desto besser wird der Bot funktionieren. Eine Möglichkeit, bessere Daten zu erhalten, besteht darin, die tatsächlichen Gespräche zu nutzen. Eine bewährte Methode ist, diaologorientierte KI-Technologie mit einem Tool zu implementieren, das Intentionen und Äußerungen, die diese Intentionen repräsentieren, aus tatsächlichen Gesprächen (aufgezeichnet oder digital) extrahiert. Es ist wichtig, eine Möglichkeit zu haben, den Bot vor der Bereitstellung zu testen und nach der Bereitstellung etwaige verpasste Intentionsidentifizierungen zu erfassen. Die Qualität der dialogorientierten KI ist nicht statisch. Bots können sich im Laufe der Zeit verbessern, wenn es eine Möglichkeit gibt, sie nach der Bereitstellung zu optimieren. Dies kann mit Standard-Bots, die eine benutzerdefinierte Entwicklung benötigen, schwierig sein. Ein großer Vorteil eines integrierten Bot-Frameworks besteht darin, dass Sie Bots, die nicht wie erwartet funktionieren, in Echtzeit und ohne Unterbrechung korrigieren können. Wenn Sie an Qualität denken, fragen Sie nach Optimierung. Ist die Optimierung automatisch? Gibt es im Prozess einen „Human in the Loop“? Wie können Sie als Unternehmen „sehen“, was passiert?
Voreingenommenheit sollte Teil der Überlegungen zur Qualität sein. Voreingenommenheit bei KI ist unvermeidbar. Wichtig ist nicht, wo Voreingenommenheit vorhanden ist (es gibt sie), sondern wie gut der Bot sie erkennen und bis zur Quelle zurückverfolgen kann. Wenn Sie ein bereits trainiertes Modell (einen Standard-Bot) verwenden, kennen Sie wahrscheinlich das Trainingsset nicht. Selbst ein großer Korpus mit einer großen Bandbreite von Inhalten aus einer Branche kann einseitig sein, wenn diese Quelle eine einzige Region oder einen bestimmten Zeitpunkt abbildet. Es gibt einige Fälle, in denen antrainierte Voreingenommenheit KI-Projekte aus der Bahn geworfen hat. Viele KI-Projekte können gar nicht genug korrigiert werden, um brauchbar zu sein. Voreingenommenheit ist von besonderem Interesse für diejenigen, die vorgeschulte große Sprachmodelle (LLMs) verwenden möchten. Der Vorteil großer, sofort einsatzbereiter Standard-Modelle besteht darin, dass sie äußerst dialogorientiert sind und mit einer Vielzahl von Gesprächsmustern in Berührung gekommen sind. Die Trainingsets sind jedoch so groß, dass sie schwer zu pflegen sind, und sie hängen von der Fähigkeit der Anbieter ab, wirklich vorurteilsfreie Daten zu finden und zu verwenden. Ein kürzlich erschienener Artikel zeigt, dass LLMs parteiisch sind – dies sollten Sie berücksichtigen, wenn Sie Fragen zu Politik oder Ereignissen stellen. Eine parteiische Voreingenommenheit könnte die Informationen, die Sie erhalten, verändern (Abbildung 3).
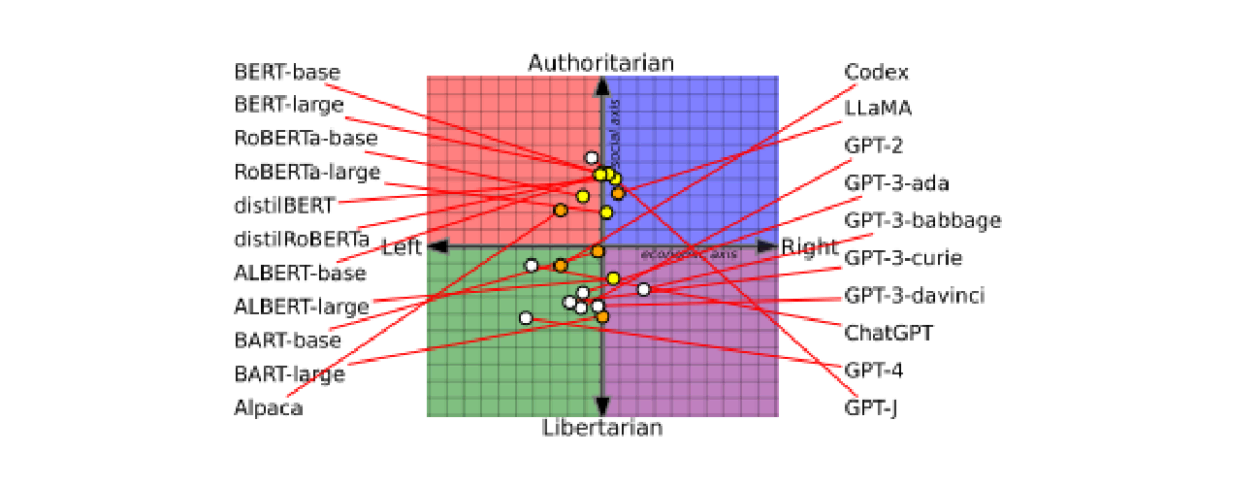
Beginnen Sie mit dem Ziel und dem Output, wenn Sie ein KI-Projekt starten. Was soll das KI-Projekt erreichen (automatisieren) und welche Auswirkungen hätte es auf diese Leistung, wenn die verwendeten Daten Voreingenommenheiten enthalten, die die Entscheidung wesentlich verändern? Beispielsweise kann Voreingenommenheit bei einem Modell, das zur Automatisierung von Kreditgenehmigungen oder Beschäftigungsverhältnissen verwendet wird, zu einer Entscheidung führen, die unethisch und wahrscheinlich in den meisten Ländern illegal ist. Die Strategie, um so etwas zu entschärfen, besteht darin, die Verwendung von Daten wie Alter, Geschlecht und ethnische Herkunft zu vermeiden. Doch oft gibt es innerhalb der Daten Dimensionen, die mit diesen geschützten Kategorien in Zusammenhang stehen und die Ergebnisse beeinflussen. So könnte eine falsche Voreingenommenheit in das Modell eingebracht werden. Bei einigen sensiblen Entscheidungen, wie z. B. Personalentscheidungen, wird der Einsatz von KI streng reguliert und überwacht (und das ist gut so). Wenn man das Ergebnis der dialogorientierten KI betrachtet, hat Voreingenommenheit möglicherweise keine wesentliche Auswirkung auf das Gespräch. Sie ist zwar zu berücksichtigen, aber ihre Auswirkungen sind wahrscheinlich nicht zu vergleichen mit den geschäftlichen Auswirkungen, die ein voreingenommenes Beschäftigungsmodell hätte. Um Voreingenommenheit zu bewerten und zu berücksichtigen, beginnen Sie mit dem Ergebnis und arbeiten Sie sich zurück zu den Daten. Die Quelle der Voreingenommenheit sind die Trainingsdaten. Ein Beschäftigungsmodell, das mit Daten aus einer Zeit trainiert wurde, in der bestimmte Gruppen von Beschäftigungsverhältnissen oder bestimmten Positionen regelmäßig ausgeschlossen wurden, wird diese Voreingenommenheit in die Gegenwart mitnehmen. Eine Möglichkeit, die Voreingenommenheit unter Kontrolle zu halten, besteht darin sicherzustellen, dass die Daten gut ausgewogen sind. Verwenden Sie für die dialogorientierte KI und für die KI-basierte Automatisierung der Customer Experience tatsächliche Gesprächsdaten aus Ihrem eigenen Kundenstamm, da diese die möglichen Gespräche abbilden. Integrierte Analysen ermöglichen es Benutzern zu beurteilen, ob es bei der Antwort des Bots eine Voreingenommenheit gibt. Wenn man beobachtet, wie Intentionen aus Äußerungen abgeleitet werden sowie welche Äußerungen verstanden werden und welche nicht, wird ersichtlich, ob ein Potenzial für Voreingenommenheit besteht. Ein integrierter Feedback-Mechanismus kann dabei helfen, Probleme zu erfassen, und die Optimierungs-Tools ermöglichen es Unternehmen, einen Bot anzupassen. Dies ist kein unbeaufsichtigter Prozess, der aus dem Ruder geraten kann. Im Gegenteil: Der Prozess ist kontrolliert, genau bedacht und es gibt einen „Human-in-the-Loop“. Das bedeutet, dass dies sowohl für hochsensible Informationen als auch für allgemeine Informationen funktionieren kann. Manche Formen von KI können nur eins von beiden umsetzen, was ihre Leistungsfähigkeit einschränkt.
Im Contact Center benötigen Sie dialogorientierte KI, die Ihren Kunden hochwertige Antworten gibt und mit der Sie geschäftliche Fortschritte erzielen können. Die Versuchung liegt nahe, nach Benchmark-Berichten und technischen Spezifikationen zu suchen. Dabei können Sie viele Daten erhalten, die möglicherweise schwer zu verstehen sind und Ihnen wahrscheinlich nicht helfen werden, Ihre Ziele zu erreichen. Es ist wichtig, eine Lösung zu haben, die die folgenden Eigenschaften aufweist:
Erfahren Sie in diesem Video mehr über den Ansatz von Genesys für dialogorientierte KI.
 Rahul Garg
Rahul Garg
Rahul joined Genesys in 2021 as VP of Product, AI and Digital Self-Service. He’s focused on building the best conversational AI products for Genesys Cloud. Prior to Genesys, he worked...
Abonnieren Sie unseren kostenlosen Newsletter und erhalten Sie alle Updates zum Genesys-Blog bequem in Ihre E-Mail-Inbox.


