Votre abonnement au Blog Genesys a bien été enregistré !
Please add genesys@email.genesys.com to your safe sender list to ensure you receive the weekly blog notifications.
Abonnez-vous à notre newsletter gratuite et recevez les nouveautés de notre blog directement dans votre boîte de réception.
Ne plus afficher.

Les utilisateurs de l’intelligence artificielle (IA) sont souvent invités à présenter leur travail. Dans le cadre de cette présentation, ils doivent prouver que leur technologie d’IA fonctionne et qu’elle peut égaler, voire même surpasser une solution d’IA alternative. Cette mission peut sembler raisonnable. Toutefois, mesurer la qualité de l’IA est une tâche complexe dans le meilleur des cas, voire parfois même tout simplement impossible. Il existe différentes mesures pour tester l’IA (taux d’erreur, mémorisation, amélioration, confiance), mais bon nombre d’entre elles sont dénuées de sens hors contexte. Parmi celles-ci, l’indicateur de performances clé en matière d’IA est le retour sur investissement.
Mais attention, cela ne signifie pas pour autant que toutes les technologies d’IA sont conçues de la même manière ou que la qualité n’est pas pertinente. En effet, la qualité de votre solution d’IA a un impact matériel sur votre capacité à utiliser l’IA pour obtenir un retour sur investissement. Dans cet article, je vais passer en revue les concepts et les références de qualité en matière d’IA, ainsi que quelques bonnes pratiques. Celui-ci peut servir de point de référence pour les utilisateurs, quelle que soit l’étape du processus de mise en œuvre de l’IA à laquelle il se trouve.
Certains s’attendent à ce que l’IA soit toujours précise. Ils pensent également à tort que l’IA corrigera les défauts humains. En effet, dans la mesure où l’erreur humaine est inévitable et attendue, l’IA doit être l’inverse. Toutefois, atteindre ce niveau de perfection est tout à fait impossible. Il est primordial de définir des attentes réalistes, de cette façon, le meilleur moyen de mesurer la réussite de l’IA est l’impact sur l’entreprise.
Au sein du centre de contact, l’IA peut accomplir certaines tâches qu’un humain ne peut pas faire. Par exemple, bien qu’un chatbot ne puisse répondre qu’à une seule question à la fois, ce dernier peut toutefois y répondre 24 h sur 24 et 7 j sur 7 sans jamais s’arrêter pour faire une pause. Si cette question est importante pour un grand pourcentage de clients, ou pour un segment de clientèle restreint mais majeur, la capacité de ce chatbot à comprendre précisément et à répondre de manière conversationnelle à un large éventail de demandes a bien plus de valeur.
Pour ce qui est de l’IA conversationnelle, si vous attendez la perfection, vous risquez d’être déçus.
En effet, les bots d’IA conversationnels s’appuient sur des données et la qualité du modèle de compréhension du langage naturel (NLU) sous-jacent dépend de l’ensemble de données utilisé pour la formation et les tests. À ce propos, vous avez peut-être vu passer des rapports qui présentent des points de référence en matière de NLU. Lorsque vous passez en revue les chiffres, assurez-vous de bien comprendre quelles données ont été utilisées.
Supposons qu’un fournisseur A ait utilisé les mêmes données de formation et de test pour l’analyse, mais que les fournisseurs B et C aient utilisé un ensemble de données de formation différent. Les résultats du fournisseur A seront probablement meilleurs que ceux des fournisseurs B et C dans la mesure où il s’appuie (essentiellement) sur l’année de naissance pour prédire l’âge : un modèle précis à 100 %, mais qui n’exploite pas pour autant tout le potentiel de l’IA.
Les modèles NLU se basent sur les critères suivants :
Dans le cas de l’IA conversationnelle, une prédiction positive correspond à ce qu’un client a dit et à ce qu’il voulait dire. L’analyse de la qualité évalue la façon dont le modèle NLU comprend le langage naturel. Elle ne mesure pas la façon dont l’IA conversationnelle répond à ce qui lui a été demandé.
Votre modèle NLU peut être capable de capturer précisément les intentions des clients. Cependant, votre structure peut ne pas être en mesure de se connecter aux systèmes dont elle a besoin pour répondre aux questions, de transférer les appels vers le canal approprié tout en préservant le contexte ou encore d’identifier la bonne réponse à la question. L’exactitude de la NLU ne permet pas de satisfaire les clients ou de résoudre les problèmes dès le premier contact.
Les scores sont généralement déterminés dans le cadre d’évaluations ponctuelles et dépendent majoritairement des données utilisées pour l’analyse. Les différences de scores peuvent être difficiles à interpréter (à moins que vous soyez un expert en modèles linguistiques). Par exemple, si un NLU obtient un score de 79 % et un autre un score de 80 %, qu’est-ce que cela signifie ? Souvent, les comparaisons publiées ne précisent pas (ou alors de manière très subtile) la portée du test ainsi que le nombre de fois où un test a été effectué et fournissent rarement les données réelles utilisées.
Si vous envisagez d’utiliser un bot prêt à l’emploi et pré-entraîné, il peut être utile de disposer de ces points de références. Notez toutefois que vous serez peut-être amenés à étendre votre évaluation dans le but d’intégrer d’autres facteurs tels que la capacité à personnaliser, analyser et optimiser. Nous reviendrons sur ce sujet plus tard.
Pour ceux qui utilisent l’IA Genesys pour créer et déployer des bots, les modèles NLU sont aussi uniques que nos clients. Ils sont formés à des fins précises comme l’utilisation de données spécifiques au client ou au cas d’utilisation que le client essaie de résoudre. Les rapports de référence standard ne rendraient pas justice à l’IA Genesys. Cependant, les équipes comparent régulièrement les performances de la NLU Genesys à d’autres NLU à l’aide d’un ensemble standard (Figure 1).
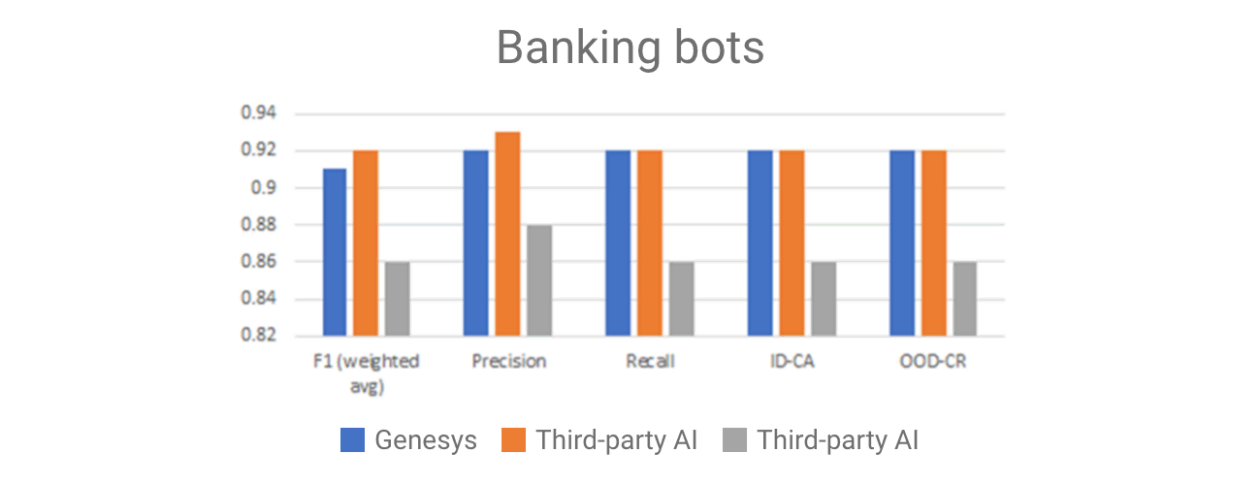
Un « bot bancaire » est formé sur la base d’un ensemble de données standard qui représente les nombreuses demandes en libre-service propres à une banque. Ce test montre que la NLU Genesys égale certaines IA tierces et qu’elle est plus performante sur ce test que d’autres. En revanche, lorsque nous étendons le test à d’autres langues, les résultats varient.
Ce test a été effectué avec le même ensemble de données traduit (par un humain) dans les différentes langues représentées ci-dessous. Lorsque vous essayez de comparer les fournisseurs de NLU en vous basant uniquement sur des points de référence, la langue est un critère important à prendre en compte. Certaines NLU fonctionnent particulièrement bien avec un ensemble de langues, mais pas avec d’autres (Figure 2).
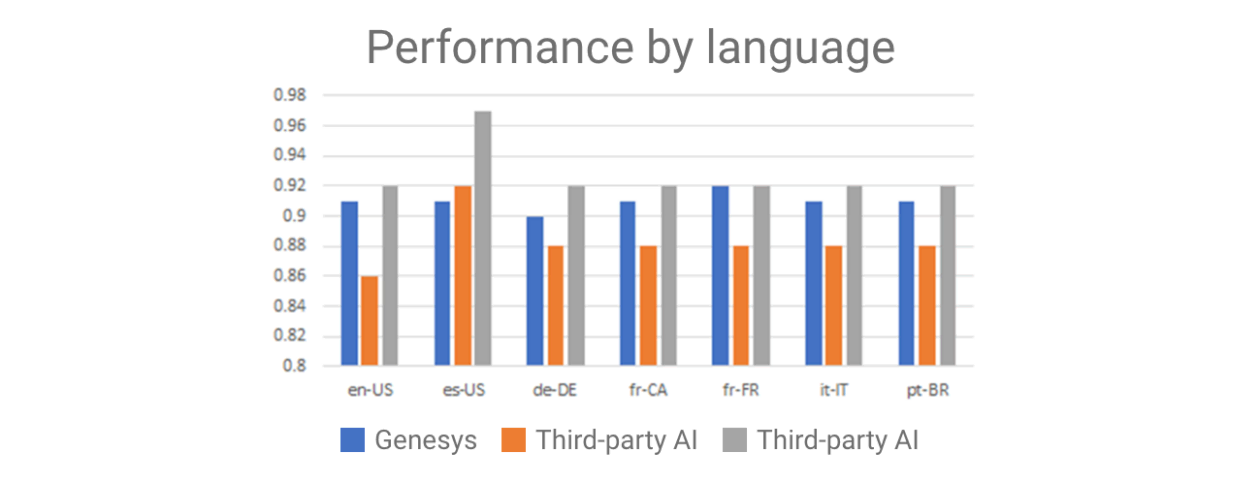
Examinez les résultats : ces résultats de test, ainsi que de nombreux autres, sont utilisés pour affiner les composants sous-jacents afin de s’assurer que les concepteurs de bots puissent atteindre le même niveau de NLU avec leur bot, voire mieux qu’avec d’autres options NLU populaires.
Les bots sont conçus pour être utilisés dans des conditions réelles, et non pas pour des ensembles de données de test. Nous devons connaître les performances d’un modèle s’appuyant sur des données représentatives de la combinaison réelle de requêtes entrantes des utilisateurs finaux pour les cas d’utilisation que le bot a été créé pour traiter. Un ensemble de tests « représentatifs » s’appuie sur un échantillon des énoncés clients réels (anonymes). Cette opération peut être manuelle ou automatisée.
La distribution des intentions sera très déséquilibrée. En effet, il existe généralement un petit nombre d’intentions qui représentent les raisons les plus fréquentes pour lesquelles les clients entrent en contact avec votre bot. Une fois que le bot a été affiné, les énoncés les plus fréquemment prononcés par les clients seront intégrés au modèle, laissant ainsi celles qui ne sont pas traitées. Ce type de test mesure les performances sur le terrain et est essentiel au maintien de la qualité au fil du temps.
Les modèles NLU sont la base des bots d’IA conversationnels. Un modèle NLU prédit l’intention de l’utilisateur final et extrait des créneaux (données) en étant formé à l’aide d’un ensemble d’exemples d’énoncés, qui se composent généralement des différentes formulations de questions potentielles d’un client.
Des outils complets de création de bots permettent au créateur de ces derniers d’ajouter et de définir les intentions et les créneaux requis pour leur bot, tout en fournissant des outils d’analyse permettant de connaître les performances des bots et des outils visant à améliorer le modèle NLU au fil du temps.
Les modèles NLU génériques parviennent à comprendre les questions de base, cependant le service client n’a rien de générique. La spécificité dont les bots ont besoin pour être efficaces s’appuie sur des (ensembles de) données de formation utilisées dans le cadre du processus de formation. Plus les données de formation se rapprochent des conversations réelles, plus le bot sera performant. L’utilisation de conversations réelles est une des techniques permettant d’obtenir de meilleures données.
Une bonne pratique consiste à mettre en œuvre une technologie d’IA conversationnelle avec un outil capable d’extraire les intentions et les énoncés qui représentent ces intentions à partir de conversations réelles, vocales ou numériques. Il est primordial de tester le bot avant de le déployer et de déceler toute identification d’intention manquée après le déploiement. La qualité de l’IA conversationnelle n’est pas figée.
En effet, la qualité des bots peut être améliorée au fil du temps s’il existe un moyen de les optimiser après le déploiement. Cependant, cette tâche peut s’avérer complexe avec les bots prêts à l’emploi qui requièrent un développement personnalisé.
L’un des principaux avantages d’une structure de bots intégrée pour les bots est qu’elle permet de corriger en temps réel et sans interruption les bots qui ne fonctionnent pas comme prévu. Lorsque vous pensez à la qualité, posez-vous les questions suivantes concernant l’optimisation : L’optimisation est-elle automatique ? Existe-t-il un processus impliquant une intervention humaine ? Comment pouvez-vous, en tant qu’entreprise, « voir » ce qui se passe ?
Lorsqu’il s’agit de qualité, vous devez tenir compte des biais, car ces derniers sont inévitables. La question majeure n’est pas de savoir à quel niveau sont ces biais (il y en a de toute façon), mais dans quelle mesure le bot peut les reconnaître et remonter à la source.
Si vous utilisez un modèle pré-entraîné (un bot prêt à l’emploi), vous ne savez probablement pas sur quel ensemble de données il s’appuie. Même un ensemble important tiré d’un large éventail de contenus du secteur peut être biaisé si cette source représente une seule zone géographique ou un point précis dans le temps. Il existe plusieurs exemples de biais intégrés qui ont fait échouer des projets d’IA. De plus, de nombreux projets d’IA ne peuvent pas être corrigés suffisamment pour être viables.
Les biais présentent un intérêt particulier pour ceux qui cherchent à utiliser de grands modèles linguistiques (LLM) pré-entraînés. Parmi les avantages de ces grands modèles prêts à l’emploi, on retrouve une grande capacité conversationnelle et une exposition à un large éventail de modes de conversation. Toutefois, les ensembles de données de formation sont si volumineux qu’ils peuvent être difficiles à gérer. De plus, ils reposent sur la capacité des fournisseurs à trouver et à utiliser des données véritablement impartiales. Un article publié récemment démontre que les LLM sont partisans : un élément que vous pouvez prendre en compte lorsque vous posez des questions sur la politique ou les événements. Notez toutefois qu’un biais partisan peut modifier les informations que vous recevez (Figure 3).
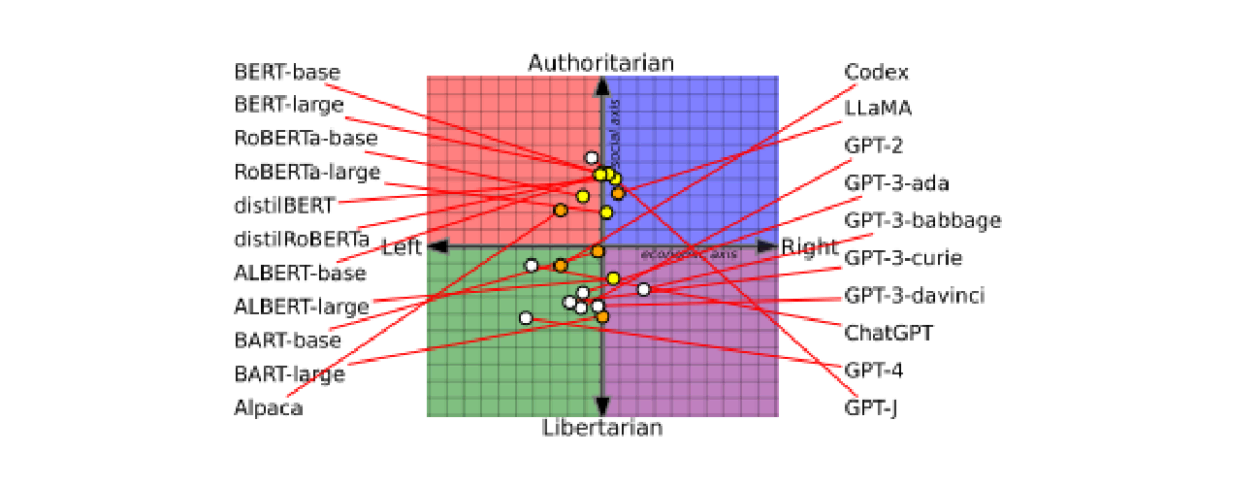
Lorsque vous vous lancez dans un projet d’IA, commencez par définir l’objectif et le résultat souhaité. Quel est l’objectif du projet d’IA (quelle tâche doit-il automatiser) et quel serait l’impact sur le résultat si les données utilisées contenaient des biais susceptibles de modifier sensiblement la décision ?
Par exemple, un modèle utilisé pour automatiser l’approbation des prêts ou le recrutement qui est biaisé peut donner lieu à une décision contraire à l’éthique et susceptible d’être illégale dans la plupart des pays. La stratégie d’atténuation consiste à éviter l’utilisation de données telles que l’âge, le sexe et l’origine raciale. Or, au sein des données, des mesures sont souvent liées à ces catégories protégées susceptibles de générer un tel résultat et introduire un mauvais type de biais dans le modèle.
Pour certaines décisions sensibles, telles que le recrutement, l’utilisation de l’IA est fortement réglementée et surveillée (comme il se doit). Lorsqu’on s’attarde sur les résultats de l’IA conversationnelle, les biais peuvent ne pas avoir d’impact significatif sur la conversation. Bien qu’ils doivent être pris en compte, il est peu probable que leur impact soit aussi important que celui d’un modèle de recrutement biaisé. Pour évaluer et prendre en compte les biais, commencez par définir le résultat souhaité et remonté jusqu’aux données.
Les données de formation sont à l’origine des biais. Un modèle de recrutement formé sur la base de données datant d’une époque où les pratiques excluaient certains groupes du recrutement ou de certaines fonctions, ne fera qu’accentuer ces biais aujourd’hui. Veiller à ce que les données soient équilibrées permet de contrôler les biais.
Pour l’IA conversationnelle ainsi que pour l’automatisation de l’expérience client basée sur l’IA, vous devez vous appuyer sur les données conversationnelles réelles de votre propre base de clients, qui représentent des conversations possibles. Les analyses intégrées permettent aux utilisateurs d’évaluer s’il existe des biais dans la façon dont le bot répond. L’observation de la manière dont les intentions sont dérivées des énoncés, de même que la comparaison entre les énoncés qui sont compris et ceux qui ne le sont pas, montreront s’il existe un potentiel de biais.
Un mécanisme de retour d’information intégré permet de détecter les problèmes éventuels et les outils d’optimisation permettent aux entreprises d’ajuster leurs bots. Il ne s’agit pas d’un processus sans surveillance qui peut se dérouler de manière anarchique.
Il s’agit d’un processus très contrôlé, mesuré et optimisé impliquant une intervention humaine. Par conséquent, celui-ci peut s’appliquer aussi bien pour les informations hautement sensibles que pour les informations générales. Certaines formes d’IA ne peuvent traiter que l’un des types d’informations, ce qui limite leur efficacité.
Les centres de contact ont besoin d’une IA conversationnelle capable de fournir une réponse de qualité à vos clients et font progresser vos objectifs commerciaux. La tentation de rechercher des rapports de référence et des spécifications techniques peut donner lieu à un grand nombre de données difficiles à comprendre et peu susceptibles de vous aider à atteindre vos objectifs.
Il est important de disposer d’une solution présentant les caractéristiques suivantes :
Apprenez-en davantage sur l’approche de Genesys en matière d’IA conversationnelle avec cette vidéo.
 Rahul Garg
Rahul Garg
Rahul joined Genesys in 2021 as VP of Product, AI and Digital Self-Service. He’s focused on building the best conversational AI products for Genesys Cloud. Prior to Genesys, he worked...
Abonnez-vous à notre newsletter gratuite et recevez les nouveautés du blog de Genesys directement dans votre boîte de réception.


